Why QuestDB?
QuestDB is an open source time-series database with a multi-tier storage engine for scale and low-latency analytics for the most demanding time-series workloads. It is built on open formats such as Parquet to avoid vendor lock-in.
Ready to try it? Jump to the quick start.
When to use QuestDB
QuestDB is designed for workloads that require:
- Continuous ingestion of time-stamped data — financial tick data, sensor readings, events
- Fast time-based queries — dashboards, real-time analytics, downsampling, high QPS
- Efficient petabyte-scale storage — multi-tier architecture with long-term storage in Parquet files
- SQL, not a new query language — standard SQL with time-series extensions
- Hardware efficiency — get more from less infrastructure
- Capital markets and crypto capabilities — N-dimensional arrays, order book analytics, OHLC charts, advanced post-trade analysis, ultra-low latency architecture, and a strong customer base in financial services
Common use cases
| Domain | Examples |
|---|---|
| Capital markets | Market data, tick-by-tick analysis, pre and post trade analytics |
| Banking | Retail banking analytics, fraud detection, transaction monitoring |
| Aerospace | Flight telemetry, satellite monitoring, rocket engine simulations |
| Energy | Grid monitoring, anomaly detection, power generation forecasting |
What makes QuestDB fast
Ingestion performance
QuestDB ingests millions of rows per second on commodity hardware.
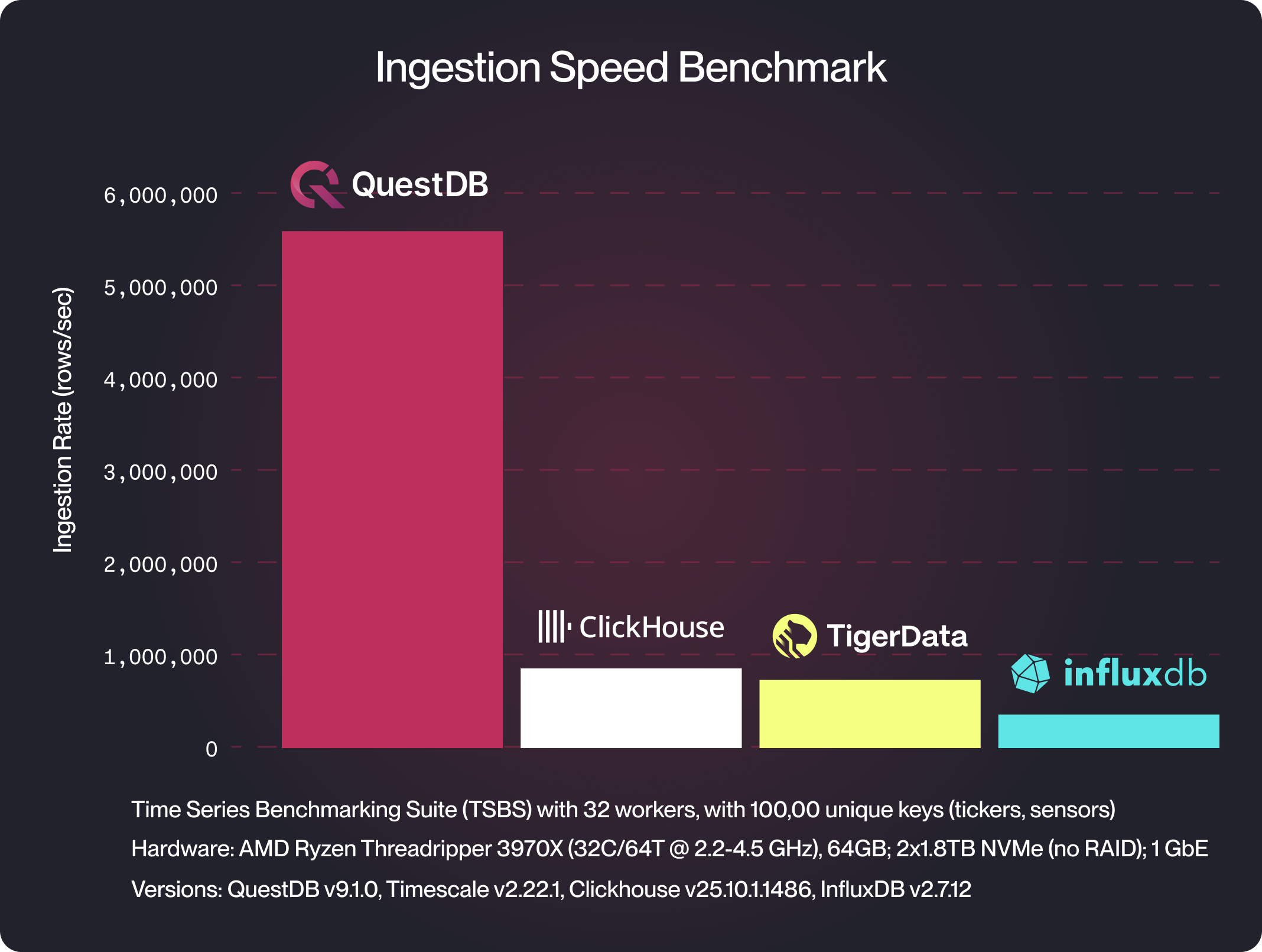
On a Raspberry Pi 5, QuestDB ingests ~270,000 rows per second.
Built-in handling for real-world data
Time-series data is messy. QuestDB handles it automatically:
- Out-of-order data — late-arriving records are merged efficiently
- Deduplication — duplicates are detected and handled at ingestion
- High cardinality — millions of unique series without performance degradation
SQL with time-series extensions
No proprietary query language. Use SQL you already know, extended for time-series:
SELECT
timestamp, symbol,
first(price) AS open,
last(price) AS close,
min(price),
max(price),
sum(amount) AS volume
FROM trades
WHERE timestamp > dateadd('d', -1, now())
SAMPLE BY 15m;
Key extensions:
SAMPLE BY— aggregate by time buckets (1 minute, 1 hour, 1 day, etc.)LATEST ON— get the most recent value per seriesASOF JOIN— join time-series by closest timestamp- Materialized Views — pre-compute aggregations automatically
When QuestDB might not be the right fit
QuestDB is optimized for time-series. Consider alternatives if:
- You need general-purpose OLTP — frequent updates, deletes, complex transactions → PostgreSQL
- Your data isn't time-series — no timestamp column, no time-based queries → traditional RDBMS
- You need full-text search — log text searching → Elasticsearch or Loki
Get started
The quick start gets you running in minutes.
Choose a client library to start ingesting:





Python
Python is a programming language that lets you work quickly and integrate systems more effectively.


Or explore more:
- Ingestion overview — all ingestion options
- Query & SQL overview — SQL reference
- Web Console — built-in SQL editor and charting
- Grafana integration — dashboards and visualization
- Capacity planning — production deployment
Support
We're happy to help:
- GitHub Issues — bug reports and feature requests
- Community Forum — questions and discussion
- Stack Overflow — tagged questions
- hello@questdb.io — direct contact